
WizardLM can wave its magic prompting Wand and lead us to the new AI possibilities.

Introduction
You’ve heard of GPT, right? The language model can write anything from tweets to essays. It’s pretty amazing, but it has one big problem: Big language models struggle with tough tasks like math, code, reasoning, and complicated data formats. This means they have limitations when it comes to advanced problem-solving. They’re not great at handling complex reasoning problems. But this also shows us where we need to improve them in the future. We need to work on their high-level capabilities.
Recently, a new model has been introduced called WizardLM, which has proven that even smaller models can outperform larger ones on certain complex tasks. In this article, we’ll explore the capabilities of WizardLM and compare it to ChatGPT and analyze why this is equivalent to chess playing Alphazero moment for Large Language models.
ChatGPT’s problem with Instruction Data Variation
To improve the performance of large language models, the instruction data for training data needs to be of various difficulty levels. ChatGPT rely upon human annotators to produce this instruction set. The whole annotating process is extremely expensive and time-consuming. On the other hand, the difficulty level distribution of human-created instructions is skewed towards being easy or moderate, with fewer difficult ones. Well, you could spend hours and hours creating instruction data with different levels of difficulty. However, the larger the model, the more difficult and time-consuming it is to train.
Why, you ask? Well, the whole annotating process is no joke. It’s like trying to find a needle in a haystack, except the needle is a difficult instruction and the haystack is a bunch of easy and moderate ones. Plus, finding human annotators who are experts in creating complex instructions is tough. And let’s not forget that humans get tired, too. They can’t keep up a high intensity of work for too long, which means they may not produce enough high-difficulty instructions.
So, what’s the solution?
Developing an automatic method that can mass-produce open-domain instructions at a low cost is the key to advancing language models.
There has to be a better way!
So researchers working on this thought exactly like this and they went and developed an automatic method to help improve our language models.
What is WizardLM and how does it work?
Evol-Instruct Method
Get ready to be spellbound by the power of WizardLM, the instruction-following language model using the Evolve Instruct method.
The magic trick behind WizardLM is a new method called Evol-Instruct. Instead of relying on humans to create instructions, this method uses large language models to automatically produce open domain instructions of varying difficulty levels.
It’s like starting with a basic spell and using the Evol-Instruct method to upgrade it into more complex spells. The instructions are mixed together to fine-tune the language model, and voila! WizardLM is born.
Despite having only 7 billion parameters (which is small in wizarding terms), the results are impressive and rival those of much larger models. With just 70,000 instruction-following data generated from the Evolve-Instruct method, WizardLM is ready to take on any task.
From math code generation to philosophy, from writing to computer science, WizardLM can handle it all. It’s like having a trusty familiar by your side, ready to cast any spell you need.
Why you should care about WizardLM?
WizardLM is a breakthrough in language modeling that shows that smaller models can achieve remarkable results on complex tasks. This could have implications for reducing the cost and time of training large models, as well as improving the quality and diversity of instruction-following applications. WizardLM is also an example of how large language models can be used to generate data for other models, creating a feedback loop of improvement.
If you are interested in learning more about WizardLM and how it works, you can read the original paper here. You can also check out some examples of WizardLM’s outputs on different tasks here.
Figure : Running Example of Evol-Instruct.
2304.12244.pdf (arxiv.org)

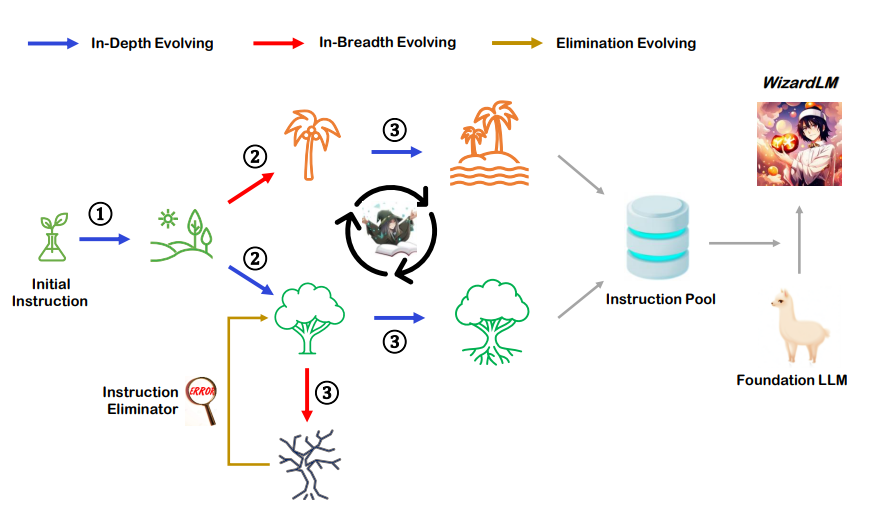
Figure 2 : Overview of the Evol-Instruct
Prompts for In-Depth Evolving
Five kinds of prompts are used to enhance instructions in different aspects: add constraints, deepening, concretizing, increase reasoning steps, and complicate input. The core part of In-Depth Evolving’s prompt is “Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4 [3]) a bit harder to handle. But the rewritten prompt must be reasonable, understood, and responded to by humans.“
Example:
I want you act as a Prompt Rewriter.
2304.12244.pdf (arxiv.org)
Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems
(e.g., chatgpt and GPT4) a bit harder to handle.
But the rewritten prompt must be reasonable and must be understood and responded by humans.
Your rewriting cannot omit the non-text parts such as the table and code in #Given Prompt#:. Also, please
do not omit the input in #Given Prompt#.
You SHOULD complicate the given prompt using the following method:
Please add one more constraints/requirements into #Given Prompt# or
If #Given Prompt# contains inquiries about certain issues, the depth and breadth of the inquiry can be
increased. or
Please replace general concepts with more specific concepts. or
If #Given Prompt# can be solved with just a few simple thinking processes, you can rewrite it to
explicitly request multiple-step reasoning.
Prompts of In-Breadth Evolving
The primary purpose of In-Breadth Evolving is to increase the topic coverage, skill coverage, and overall diversity of the current instruction dataset.
Example :
I want you act as a Prompt Creator. Your goal is to draw inspiration from the #Given Prompt# to create a brand new prompt. This new prompt should belong to the same domain as the #Given Prompt# but be even more rare. The LENGTH and difficulty level of the #Created Prompt# should be similar to that of the #Given Prompt#. The #Created Prompt# must be reasonable and must be understood and responded by humans. ‘#Given Prompt#’, ‘#Created Prompt#’, ‘given prompt’ and ‘created prompt’ are not allowed to appear in #Created Prompt#. #Given Prompt#:
2304.12244.pdf (arxiv.org)
How WizardLM performs in comparison with ChatGPT?
WizardLM provides a web demo (demo 1, demo 2 ) where users can experiment with the model. The researchers ran tests on the model to compare its performance with ChatGPT. In one test, they asked both models to generate a list of three startup ideas with a strong and compelling mission and avoid cryptocurrency or blockchain. The results were impressive, with both models generating some great ideas.
However, WizardLM performed better than ChatGPT on a more complex task, indicating its ability to outperform larger models on certain specific tasks.

WizardLM-13B Uncensored Model Release
In the realm of natural language processing, the WizardLM 13 billion model (WizardLM-13B) stands as a remarkable achievement. This powerful language model has captivated the attention of researchers and enthusiasts alike, offering new avenues for creativity, problem-solving, and information retrieval.
WizardLM-13B is designed to remove alignment and moralizing elements from the dataset. However, as with any extraordinary tool, its potential impact necessitates responsible usage.
The primary goal was to craft a model that does not possess built-in alignment, allowing alignment of any kind to be added independently. As per the release notes, this intentional omission enables greater flexibility and customization, facilitating the exploration of diverse applications, ranging from entertainment to education and beyond.
Conclusion
WizardLM is a breakthrough in language modeling that could have implications for reducing the cost and time of training large models, as well as improving the quality and diversity of instruction-following applications.
For very specific tasks, we might be able to train task-specific models to outperform much larger generalized models. For example, imagine a model specifically trained on only mathematics; that model can be much smaller, but it will outperform models like ChatGPT or even GPT-4 because those are more general models and not trained on a specific task.
In conclusion, WizardLM has proven that even smaller models can be highly effective on specific tasks. While larger models like ChatGPT may perform better overall, WizardLM has shown that it can beat ChatGPT on certain tasks. As language models continue to evolve, we may see more task-specific models that can perform even better than the general ones.








Thank you for the auspicious writeup. It in fact was a amusement account
it. Look advanced to far added agreeable from you! By the way, how could we communicate?
Hi friends, how is all, and what you wish for to say about
this post, in my view its truly amazing designed for me.
Thanks in support of sharing such a good opinion, article
is fastidious, thats why i have read it fully
Please let me know if you’re looking for a article writer for
your site. You have some really great articles and I think I would be a good asset.
If you ever want to take some of the load off, I’d really like to write some material for
your blog in exchange for a link back to mine. Please blast me an e-mail if interested.
Regards!
Wow, that’s what I was seeking for, what
a information! present here at this webpage, thanks admin of
this web site.
What a material of un-ambiguity and preserveness of valuable know-how
about unpredicted feelings.
Thanks for sharing your thoughts about how to buy instagram followers
for free?. Regards